
More Mythos and Mozilla

I have been using Mozilla based products continuously since 1993. Back then the browser was called Mosaic. It morphed into Netscape, which open-sourced the software now maintained by Mozilla.org (Mosaic + Godzilla = Mozilla).

I am so happy that an organization that pioneered free and open software is still thriving and leading the way, as evidenced by their rapid adaption of Claude Mythos Preview for vulnerability management which I wrote about in We Are Doing This.
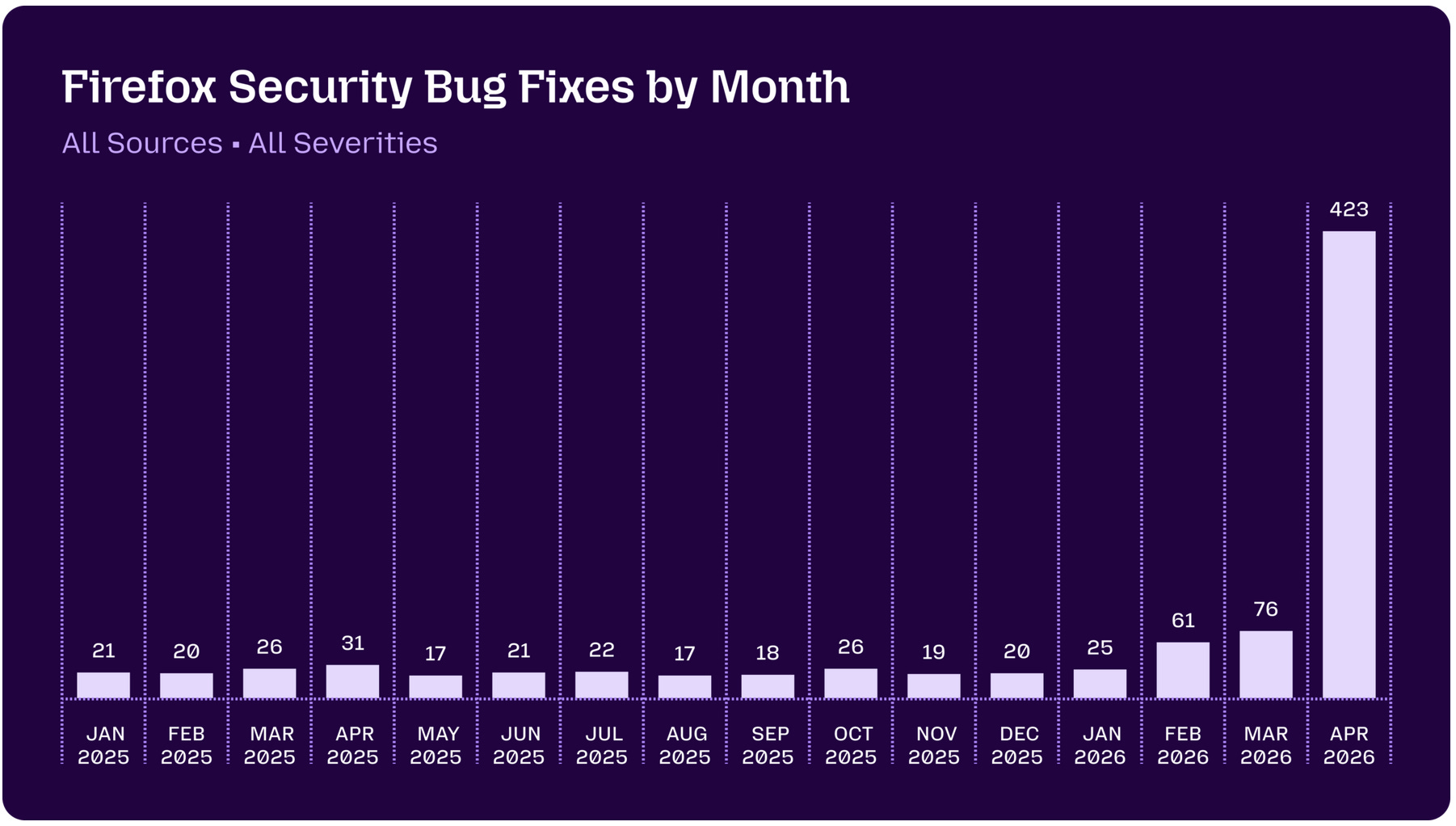
This past week we were treated to more visibility into how Mozilla was able to find and patch 271 security issues in Firefox 150 using Mythos
.
This week the team at Mozilla shared more details. What they have built and are using should be a guide to any team responsible for pushing out applications. You may not have access to Mythos today, but you could be using any of the latest frontier models to get ahead of the curve so that, like Mozilla, you can swap out Mythos when you get it. I predict that by July you will have full access to models that are at least as good as Mythos for code analysis.
Here is the “advice for other projects on making good use of emerging capabilities to harden themselves against attack” that the Mozilla team put together.
They start by pointing out that just a few months ago AI was garbage at reliably identifying bugs in code. That has changed. Just read the descriptions of a few of the newly discovered bugs.
An incorrect equality check can cause the JIT to optimize away the initialization of a live WebAssembly GC struct, creating a fake-object primitive with potential arbitrary read/write in code that had undergone extensive fuzzing by internal and external researchers.
A 15-year-old bug in the <legend> element triggered by meticulous orchestration of edge cases across distant parts of the browser, including recursion stack depth limits, expando properties, and cycle collection.
Simulates a malicious DNS server by intercepting glibc DNS function calls in order to reproduce a UDP->TCP fallback edge case, triggering a buffer over-read and parent-process stack memory leak during HTTPS RR & ECH parsing.
These are astounding results. Here is a statement from Stephanie Domas, VP Security at Mozilla:
The numbers tell that story better than I can. One year ago: 31 security fixes in a release. April 2026: 423. Same team. Same codebase. Completely different leverage.
What made this possible wasn't just dropping an AI on the Firefox source tree. The team built a real pipeline — agentic harness, dynamic test case generation, deduplication, triage, patch validation, release integration — and ran it across distributed VMs in parallel.
And the defense-in-depth work Firefox has invested in for years? It showed up. Mythos repeatedly tried to pursue prototype pollution escape paths — and was thwarted by architectural changes the team had already made. Prior hardening work compressing the attack surface, great validation.
…the future isn't unknowable chaos — it's still a race, just a faster one. I believe that more now. The economics of finding bugs have changed. The question is whether defenders move as fast as the tools let them.
The message is clear to vulnerability teams at software companies. Get moving. Especially now that your dev teams are already using Claude Code to speed up the CI/CD cycle.
But what about vulnerability management teams at large enterprises? Yes, there will be bigger and more frequent updates coming for all of your software. You too will have to build “a real pipeline — agentic harness, dynamic test case generation, deduplication, triage, patch validation, release integration — and run it across distributed VMs in parallel.”
But get ready for the next Mythos-level evolution. Before the end of the year I predict frontier models will be identifying vulnerabilities in compiled code at such a level of accuracy that enterprise security teams are going to be severely challenged.* They will finally have the tools to check software updates from vendors. This will stop most future Notpetyas and Solarwinds attacks. But only if a new discipline is introduced to inspect and test software updates.
According to IT-Harvest’s database of 11,400 cybersecurity products there are 241 vendors of vulnerability management solutions. Are their tools going to be fit-for-purpose by the end of the year?
Legacy vuln-management is mostly accounting.
Scan everything to discover software versions.
Look up the known vulns in the software detected.
Enrich that data with knowledge of severity and if it is being actively exploited.
Create a list of vulns stack ranked by urgency. This list is often over 40,000 vulnerabilities.
These tasks are easily enhanced by AI. In Guardians of the Machine Age I describe the 29 AI Security startups that are addressing vulnerability management.
Most of these stop short of actually patching vulnerable systems. Understandably so, because patching, updating, testing, are the hard parts. But they are great at prioritizing fixes and posting them to Jira.
The challenge will be scaling the ability to close those tickets quickly.
* An April 7 post by Anthropic gives us some visibility into Mythos and binaries:
We have also found the model to be extremely capable of reverse engineering: taking a closed-source, stripped binary and reconstructing (plausible) source code for what it does. From there, we provide Mythos Preview both the reconstructed source code and the original binary, and say, “Please find vulnerabilities in this closed-source project. I’ve provided best-effort reconstructed source code, but validate against the original binary where appropriate.”
Excellent post! IT teams were already hating Vulnerability Management teams… now, they better start to work together properly…